実験データなどの誤差を含んだ値から, 最もフィットする関数を計算する手法が最小二乗法(method of least squares)です. 一番簡単なのは,直線で近似する方法です.
たとえば等速直線運動を観察した実験で,つぎのような測定データが得られたとします.
| 時間 (s) | 位置 (m) |
|---|---|
| 0.0 | 1.0 |
| 0.2 | 1.9 |
| 0.4 | 3.2 |
| 0.6 | 4.3 |
| 0.8 | 4.8 |
| 1.0 | 6.1 |
| 1.2 | 7.2 |
横軸に時間,縦軸に位置をとり,これをグラフにしてみます (説明のため,グラフ中では横軸を x,縦軸を y と書いています).
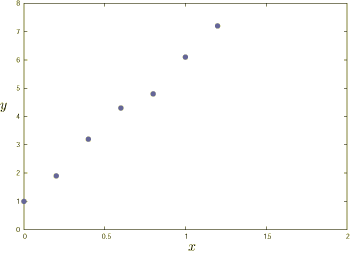
厳密な等速直線運動ならば,このデータは直線で結ばれ,その傾きは速度を表します. しかし実験には誤差がつきもので,ものさしの誤差, 測定者のくせによる誤差,測定環境の変化による誤差など,いろいろな誤差が存在します. ですから,測定データは一直線上には並びません.だからといってデータの各点を
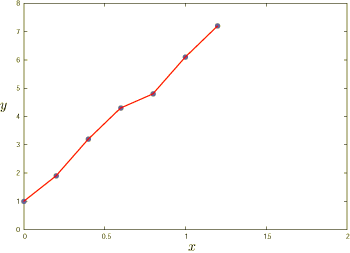
のように繋げて折れ線グラフにしてもあまり意味がありません. このグラフの傾きは速さを表すはずですが, 折れ線グラフから傾きを求めることはできないですし, そもそも誤差を含んでいる点をそのまま結んでも仕方がありません.そこで
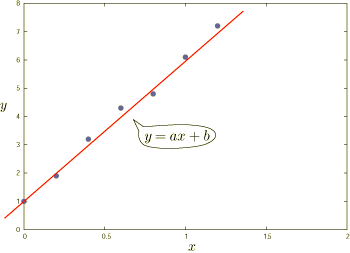
のようにどのデータポイントからもあまり外れないように直線を引くのが妥当だといえます. 直線は1次関数ですから y = ax + b とおけるハズです. 目分量でものさしを当てて直線を引いてもいいのですが(上の図の直線は目分量で描きました), それでは人によって傾きが変化しますし,あいまいな感じがします. もう少し機械的に直線を引く方法が欲しいですよね.それが最小二乗法です.
n 個のデータ
に最もフィットする直線を
とすると,係数 a と b は
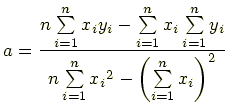
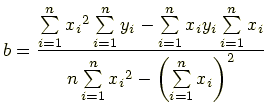
によって決定することができます. 数値計算ではこれらの式から a と b の値を計算します. なぜ「最小二乗」なのかというと,上の式を求めるときに 「直線と各データポイントの差の二乗を最小にする」 という手法が使われているからです(上式の導出は省略します).
データの数を7個とし,各点の値を配列に納めたプログラム例はつぎのようになります. 赤字がアルゴリズムに直接関係した部分です.
#include <stdio.h>
#include <math.h>
#define N 7 /* データ数 */
int main(void) {
int i;
double x[N] = { 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2 };
double y[N] = { 1.0, 1.9, 3.2, 4.3, 4.8, 6.1, 7.2 };
double a = 0, b = 0;
double sum_xy = 0, sum_x = 0, sum_y = 0, sum_x2 = 0;
for (i=0; i<N; i++) {
sum_xy += x[i] * y[i];
sum_x += x[i];
sum_y += y[i];
sum_x2 += pow(x[i], 2);
}
a = (N * sum_xy - sum_x * sum_y) / (N * sum_x2 - pow(sum_x, 2));
b = (sum_x2 * sum_y - sum_xy * sum_x) / (N * sum_x2 - pow(sum_x, 2));
printf("a = %f\n", a);
printf("b = %f\n", b);
return 0;
}
このプログラムは直線の傾き a と切片 b をアルゴリズムの通りに計算しているだけです. 実行するとつぎの出力が得られます.
a = 5.107143 b = 1.007143
この結果から,直線は y = 5.11x + 1.01 と書けます. その直線をグラフに書き込むとつぎのようになります.
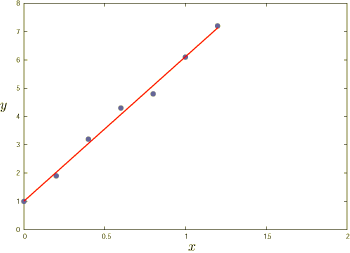
ご覧の通り,もっともらしい直線が引けました. データポイントが多い場合はプログラムソース中に直接値を書くのではなく, 外部のファイルから読み込むようにすればよいでしょう.
ちなみにこの例では,等速直線運動を観察したという設定ですので, 直線の関数 y = 5.11x + 1.01 の 5.11 が速さ[m/s],1.01 が初期位置[m]となります.